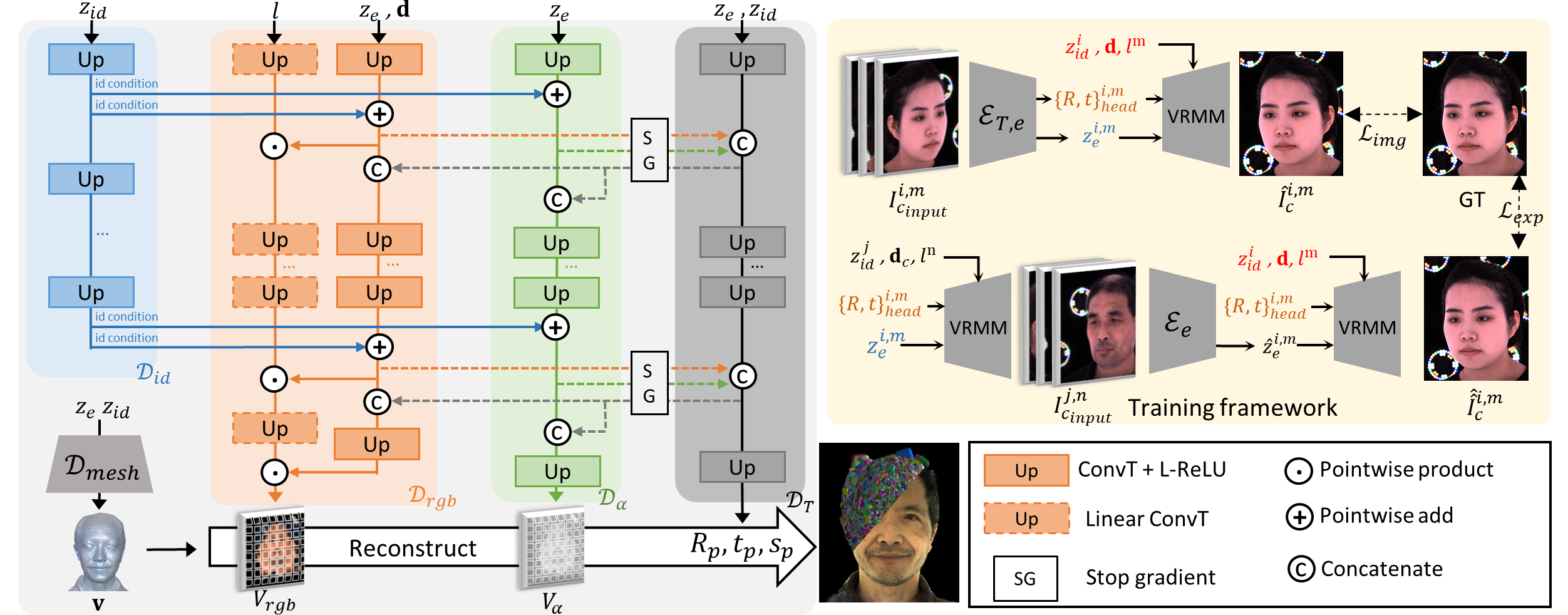
In this paper, we introduce the Volumetric Relightable Morphable Model (VRMM), a novel volumetric and parametric facial prior for 3D face modeling. While recent volumetric prior models offer improvements over traditional methods like 3D Morphable Models (3DMMs), they face challenges in model learning and personalized reconstructions. Our VRMM overcomes these by employing a novel training framework that efficiently disentangles and encodes latent spaces of identity, expression, and lighting into low-dimensional representations. This framework, designed with self-supervised learning, significantly reduces the constraints for training data, making it more feasible in practice. The learned VRMM offers relighting capabilities and encompasses a comprehensive range of expressions. We demonstrate the versatility and effectiveness of VRMM through various applications like avatar generation, facial reconstruction, and animation. Additionally, we address the common issue of overfitting in generative volumetric models with a novel prior-preserving personalization framework based on VRMM. Such an approach enables high-quality 3D face reconstruction from even a single portrait input. Our experiments showcase the potential of VRMM to significantly enhance the field of 3D face modeling.
@inproceedings{yang2024vrmm,
title={VRMM: A Volumetric Relightable Morphable Head Model},
author={Haotian, Yang and Mingwu, Zheng and ChongYang, Ma and Yu-Kun, Lai and Pengfei, Wan and Haibin, Huang},
booktitle={SIGGRAPH 2024 Conference Proceedings},
year={2024}
}